

ADAM 0.25.0 and Cannoli 0.3.0 Released
ADAM version 0.25.0 and Cannoli version 0.3.0 have been released!
Since the 0.24.0 release of ADAM, more then 40 issues have been closed, including bug fixes around indexed reads and attributes in VCF. New features include additional filter by methods and multi-sample coverage. The ADAM Python APIs now support Python 3.
Based on feedback from the 2018 GCCBOSC bioinformatics community conference,
at 2018 GCCBOSC CollaborationFest the Cannoli API
was refactored to greatly improve interactive use in cannoli-shell (a Scala REPL based on Spark Shell, similar
to adam-shell) and notebooks such as Jupyter, Zeppelin,
and Spark Notebook.
For example, here is an entire variant calling pipeline, based on bwa, ADAM, and Freebayes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Changes since Previous Releases
The full list of changes to ADAM since version 0.24.0 and Cannoli since version 0.2.0 are below.
ADAM 0.24.0 and Cannoli 0.2.0 Released
ADAM version 0.24.0 and Cannoli version 0.2.0 have been released!
As of version 0.24.0, support for Spark version 1.x and Scala 2.10.x has been dropped. ADAM and Cannoli currently build against Spark version 2.3.0 and Scala version 2.11.12.
Major new features in ADAM version 0.24.0 include Spark SQL support across all genomic data types and access to the ADAM region join API through Python and R. The ADAM Python and R APIs are now feature complete relative to ADAM’s Java API. ADAM version 0.24.0 also introduces Hive-style partitioning by genomic range for Parquet-backed Datasets. This greatly improves performance for genomic range based queries.
With version 0.2.0, Cannoli now provides a functional API for interactive use in
cannoli-shell (a Scala REPL based on Spark Shell, similar to adam-shell) and
notebooks such as Jupyter, Zeppelin,
and Spark Notebook. This API allows for multiple
Cannoli-wrapped bioinformatics tools as processes in a larger Spark-based workflow
without having to write out to disk intermediately.
Changes since Previous Releases
The full list of changes to ADAM since version 0.23.0 and Cannoli since version 0.1.0 are below.
ADAM 0.23.0 Released (+ Avocado and DECA Releases)
We are excited to announce the availability of the ADAM 0.23.0 release, along with releases of Avocado germline variant caller (release 0.1.0) and the DECA copy number variant caller (release 0.2.0). These releases contain an extensive number of feature additions, performance improvements, and bug patches, with over 375 issues closed and pull requests merged or closed since the last ADAM release.
Some of the highlights include:
- A validated, high-performance end-to-end alignment/variant calling pipeline using ADAM, Cannoli, and Avocado.
- Support for manipulating data using Spark SQL.
- R and Python APIs for ADAM, including the ability to get a working deployment
of ADAM simply by running
pip install bdgenomics.adam.
With this release, we have also moved our documentation to Read The Docs:
This documentation describes how to deploy our tools on a variety of platforms,
including a local cluster, cloud computing, and through the
Toil workflow manager. We already have
a pip installable Toil workflow for calling copy number variants with DECA,
which is packaged as part of the
bdgenomics.workflows library.
This release is the last release of ADAM that supports Spark 1.x and Scala 2.10. The upcoming release of ADAM will only support Spark 2.x and Scala 2.11. Avocado and DECA have already dropped support for Spark 1.x.
Over the upcoming few weeks, we are working on a release of Cannoli, as well as Toil workflows for running the ADAM/Avocado/Cannoli variant calling pipeline, and a preprint describing the pipeline in more depth. We also are working on a release of the Mango visualization tool, which uses ADAM as a backend for interactively visualizing large genomics datasets. Stay tuned for more info!
Variant Calling with Cannoli, ADAM, Avocado, and DECA
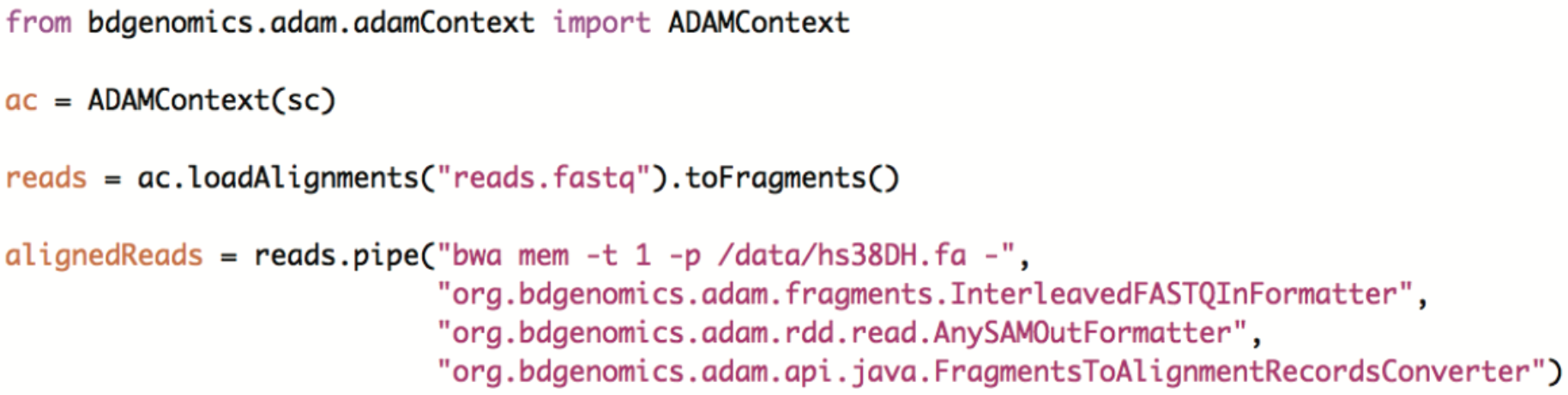
With the collection of tools we have released, you can run highly rapid and accurate variant calling entirely in Apache Spark. While we have introduced Avocado and DECA earlier in this post, we haven’t talked about Cannoli yet. Cannoli—-Italian for “a little pipe”—-uses ADAM’s pipe API to parallelize commonly used genomics tools. Currently, Cannoli supports aligning reads with Bowtie, Bowtie2, and BWA; calling variants with FreeBayes; and annotating variant effects with SnpEff. We are working on support for many more tools, as you can see in our issue tracker. Please let us know if you are interested in any specific tool—-or even better—-in helping us add support for a specific tool. ADAM’s pipe API makes it extremely easy to parallelize an existing single node genomic analysis tool, and most tools can be implemented on top of the pipe API in less than 10 lines of code. For example, here’s how you could launch BWA using ADAM’s Pipe API in Python:
By using Cannoli, we can accelerate alignment with BWA to take approximately 10—15 minutes when running on a 1,024 core cluster.
We can couple this rapid alignment pipeline with the fast preprocessing stages in ADAM and the variant calling stages in Avocado to call variants on a 60x coverage WGS dataset in approximately 45 minutes on a 1,024 core cluster. Avocado can be used to call variants on a single sample, or to jointly call variants using a gVCF-based workflow. When running on 1,024 cores, we were able to jointly genotype more than 10TB of gVCFs within approximately 6 hours. Avocado has >99% accuracy when genotyping SNPs, and >96% accuracy when genotyping INDELs. Detailed benchmarking results can be found in Chapter 8 of this thesis. Avocado is two times faster than the GATK4’s Spark-based implementation of the HaplotypeCaller, although it is worth pointing out that this is an unfair comparison, as the HaplotypeCaller performs local reassembly, while Avocado does not.
One interesting comparison is between the duplicate marking and BQSR tools in ADAM and in the GATK4. In both cases, ADAM’s implementation is faster than the GATK4’s equivalent implementation.
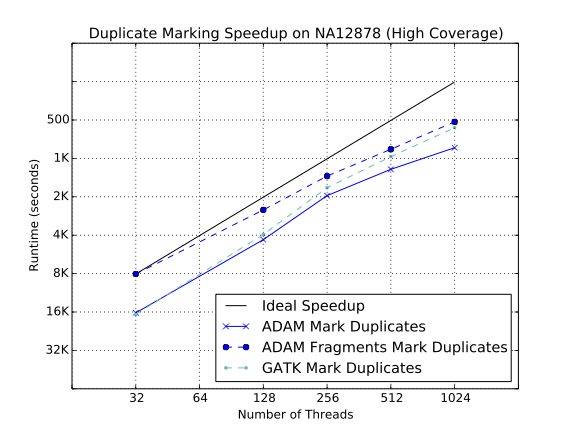
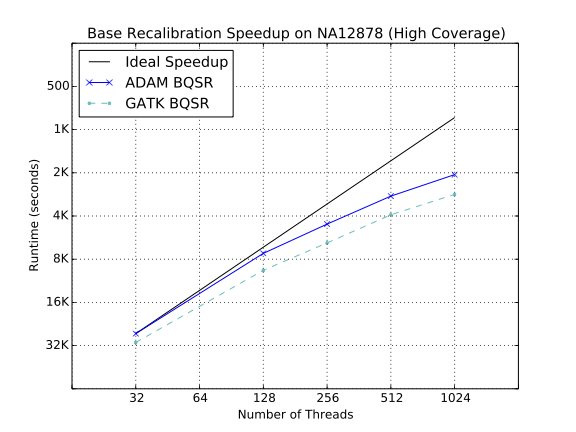
We have work-in-progress towards a Spark SQL-based implementation of duplicate marking, which will provide an additional >20% performance improvement. We hope to introduce this new duplicate marker in the 0.24.0 release of ADAM.
Manipulating Data using Spark SQL
Since Apache Spark 1.6, there has been a major push in the Spark project to rearchitect Spark around the Catalyst query optimizer and the Tungsten code execution engine. These two engines are hidden behind Spark SQL’s DataFrame and Dataset APIs, which provide a SQL-like interface for manipulating data using Spark. Unlike Spark’s Resilient Distributed Dataset (RDD) API, the DataFrame API allows the Catalyst query optimizer to examine the function that the user is running. Catalyst can then rewrite the query so that it runs in a more efficient manner, and can implement the query using the Tungsten engine with performance that approaches native performance. This can provide order-of-magnitude performance improvements for some queries, and it also provides users with uniform query performance across Scala, Java, SQL, Python, and R.
Although Spark SQL was introduced in 2015, we were not able to take advantage
of Spark SQL in ADAM until recently. While ADAM has always described genomics
data using a set of schemas, the library we used to represent these schemas
(Apache Avro) was not compatible with Spark SQL. To
resolve this, we updated our core GenomicRDD interfaces
to transparently convert between Spark’s RDD and DataFrame/Dataset APIs. We
describe the architecture we use for converting between these two representations
here.
With the Spark SQL query interfaces built into GenomicRDDs, you can begin
running SQL queries on genomic data in fewer than 5 lines of code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | |
While Spark SQL has specific optimizations for loading data from Apache Parquet files, ADAM can be used to run Spark SQL queries against data stored in most common genomics file formats, including SAM/BAM/CRAM, FASTQ, VCF/BCF, BED, GTF/GFF3, IntervalList, NarrowPeak, FASTA and more.
Using ADAM through Python and R
As mentioned above, one of the major advantages of Spark SQL is that it provides
uniform query performance across Scala, Java, Python, and R. While ADAM is
mostly written in Scala, we have maintained Java APIs for a long time. However,
we have previously been unable to support Python or R APIs. Adding support
for Spark SQL eliminated the major issues that prevented us from adding Python
and R APIs. This release of ADAM introduces the bdgenomics.adam packages for
Python and R. Our Python API can be installed using pip install
bdgenomics.adam, and our R API is available from
GitHub.
We hope to make our R API available through CRAN in the 0.24.0 release of ADAM;
we are blocked on an issue upstream in Apache Spark and are tracking progress on
this issue at ADAM-1851.
In addition to installing the bdgenomics.adam libraries, running pip install
bdgenomics.adam installs all of the ADAM command line tools:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | |
Most of the major APIs in ADAM can be used through our Python and R bindings, with the exception of the region join API. We plan to enable the use of the region join API in Python and R in the 0.24.0 release of ADAM, along with other API compatibility improvements.
Changes since Previous Release
The full list of changes since version 0.22.0 is below.
ADAM 0.22.0 Released
ADAM version 0.22.0 has been released!
Due to major changes between Spark versions 1.6 and 2.0, we build for combinations of Apache Spark and Scala versions: Spark 1.x and Scala 2.10, Spark 1.x and Scala 2.11, Spark 2.x and Scala 2.10, and Spark 2.x and Scala 2.11.
The focus of this release was performance, including major improvements to BQSR and INDEL realignment.
More than 80 other issues were closed in this release, including bug fixes around VCF validation and paired end FASTQ parsing and new features such as pipe API support for features.
The full list of changes since version 0.21.0 is below.
ADAM 0.21.0 Released
ADAM version 0.21.0 has been released!
Due to major changes between Spark versions 1.6 and 2.0, we now build for combinations of Apache Spark and Scala versions: Spark 1.x and Scala 2.10, Spark 1.x and Scala 2.11, Spark 2.x and Scala 2.10, and Spark 2.x and Scala 2.11. The Spark 2.x build-time dependency will be bumped to version 2.1.0 in the next release of ADAM, see issue #1330.
One focus of this release was documentation, both at the developer API level, including extensive javadoc and scaladoc source code comments, and at the user level (e.g. https://github.com/bigdatagenomics/adam/tree/master/docs/source). The user docs can be compiled to PDF or HTML with pandoc, but to be honest they look better rendered as Markdown on Github.
Another focus was to more closely follow the VCF specification(s) when reading from and writing to VCF. For this we made significant changes to our variant and variant annotation schema and added support for version 1.0 of the VCF INFO ‘ANN’ key specification. This work will continue for our genotype and genotype annotation schema in the next version of ADAM.
The full list of changes since version 0.20.0 is below.
ADAM 0.20.0 Released
ADAM version 0.20.0 has been released!
Due to major changes between Spark versions 1.6 and 2.0, we now build for combinations of Apache Spark and Scala versions: Spark 1.x and Scala 2.10, Spark 1.x and Scala 2.11, Spark 2.x and Scala 2.10, and Spark 2.x and Scala 2.11.
Since the last release, version 0.19.0, we have closed more than 180 issues and merged more than 120 pull requests.
We added a new pipe API, allowing for streaming alignment and variant records out to external applications and streaming back in the results. Several new region join implementations are now public API, including a broadcast inner join, broadcast right outer join, sort-merge inner join, sort-merge right outer join, sort-merge left outer join, sort-merge full outer join, sort-merge inner join followed by a group by, and a sort-merge right outer join followed by a group by.
Alignment records can now be read from and written to CRAM format. We updated upstream dependencies on Hadoop-BAM and htsjdk to fix various alignment record header bugs and to add support for gzip and BGZF compressed VCF.
Our sequence feature schema now more closely follow the GFF3 specification, while still supporting BED, GFF2/GTF, IntervalList, and NarrowPeak formats. We also added a new sample schema for e.g. SRA sample metadata.
With this version the core ADAM APIs are undergoing a major refactoring. We changed many method names on ADAMContext to make the API more consistent. We also added RDD wrapper classes to increase performance by serializing metadata (such as record groups, samples, and sequence dictionaries) to disk separate from primary data in Parquet. API incompatibilities between ADAM releases will settle down by the 1.0 release, currently targeted for early 2017.
The full list of changes since version 0.19.0 is below.
ADAM 0.19.0 Released
ADAM version 0.19.0 has been released, built for both Scala 2.10 and Scala 2.11.
The 0.19.0 release contains various concordance fixes and performance improvements for accessing read metadata. Schema changes, including a bump to version 0.7.0 of the Big Data Genomics Avro data formats, were made to support the read metadata performance improvements. Additionally, the performance of exporting a single BAM file was improved, and this was made to be guaranteed correct for sorted data.
ADAM now targets Apache Spark 1.5.2 and Apache Hadoop 2.6.0 as the default build environment. ADAM and applications built on ADAM should run on a wide range of Apache Spark (1.3.1 up to and including the most recent, 1.6.0) and Apache Hadoop (currently 2.3.0 and 2.6.0) versions. A compatibility matrix of Spark, Hadoop, and Scala version builds in our continuous integration system verifies this. Please note, as of this release, support for Apache Spark 1.2.x and Apache Hadoop 1.0.x has been dropped.
The full list of changes since version 0.18.2 is below.
ADAM 0.18.2 Released
A few ADAM releases have been made since the last announcement; we’ll attempt to catch up here.
The most recent is a version 0.18.2 bugfix release, built for both Scala 2.10 and Scala 2.11. It fixes a minor issue with the binary distribution artifact from version 0.18.1.
Prior to version 0.18.2, we made significant changes to support version 0.6.0 of the Big Data Genomics Avro data formats. We also improved performance on core transforms (markdups, indel realignment, bqsr) by using finer grained projection. Some issues in 2bitfile when dealing with gaps and masked regions were fixed. Round-trip transformations from native formats (e.g., FASTA, FASTQ, SAM, BAM) to ADAM and back have been improved. We made extending ADAM more straightforward.
ADAM now runs on a wide range of Apache Spark (1.2.1 up to and including the most recent, 1.5.1) and Apache Hadoop (currently 1.0.4, 2.3.0 and 2.6.0) versions. This is verified by a compatibility matrix of Spark, Hadoop, and Scala version builds in our continuous integration system.
The full list of changes since version 0.17.0 is below.
Genomic Analysis Using ADAM, Spark and Deep Learning
Special thanks to Neil Ferguson for this blog post on genomic analysis using ADAM, Spark and Deep Learning
Can we use deep learning to predict which population group you belong to, based solely on your genome?
Yes, we can – and in this post, we will show you exactly how to do this in a scalable way, using Apache Spark. We will explain how to apply deep learning using artifical neural networks to predict which population group an individual belongs to – based entirely on his or her genomic data.
This is a follow-up to an earlier post: Scalable Genomes Clustering With ADAM and Spark and attempts to replicate the results of that post. However, we will use a different machine learning technique. Where the original post used k-means clustering, we will use deep learning.
We will use ADAM and Apache Spark in combination with H2O, an open source predictive analytics platform, and Sparking Water, which integrates H2O with Spark.
ADAM 0.17.0 Released
The 0.17.0 release of ADAM includes a release for Scala 2.10 and a release for Scala 2.11. We’ve been working to cleanup APIs and simplify ADAM for developers. Code that isn’t useful has been removed. Code that belongs in other downstream or upstream projects has been moved. Parquet and HTSJDK has been upgraded.
There are also some new features, e.g. you can now now transform all the SAM/BAM files in a directory by specifying the directory and there’s a new flatten command that allows you to flatten the schema of ADAM data to process in Impala, Hive, SparkSQL, etc; there are also many bug fixes.